
In a groundbreaking examine, researchers from the Commonwealth Scientific and Industrial Analysis Organisation (CSIRO) and The College of Queensland have unveiled the vital impression of immediate variations on the accuracy of well being data supplied by Chat Generative Pre-trained Transformer (ChatGPT), a state-of-the-art generative giant language mannequin (LLM). This analysis marks a major development in our understanding of how synthetic intelligence (AI) applied sciences course of health-related queries, emphasizing the significance of immediate design in making certain the reliability of the data disseminated to the general public.
As AI turns into more and more integral to our each day lives, its capacity to supply correct and dependable data, significantly in delicate areas resembling well being, is beneath intense scrutiny. The examine carried out by CSIRO and The College of Queensland researchers brings to gentle the nuanced methods wherein the formulation of prompts influences ChatGPT’s responses. Within the realm of well being data searching for, the place the accuracy of the data can have profound implications, the findings of this examine are particularly pertinent.
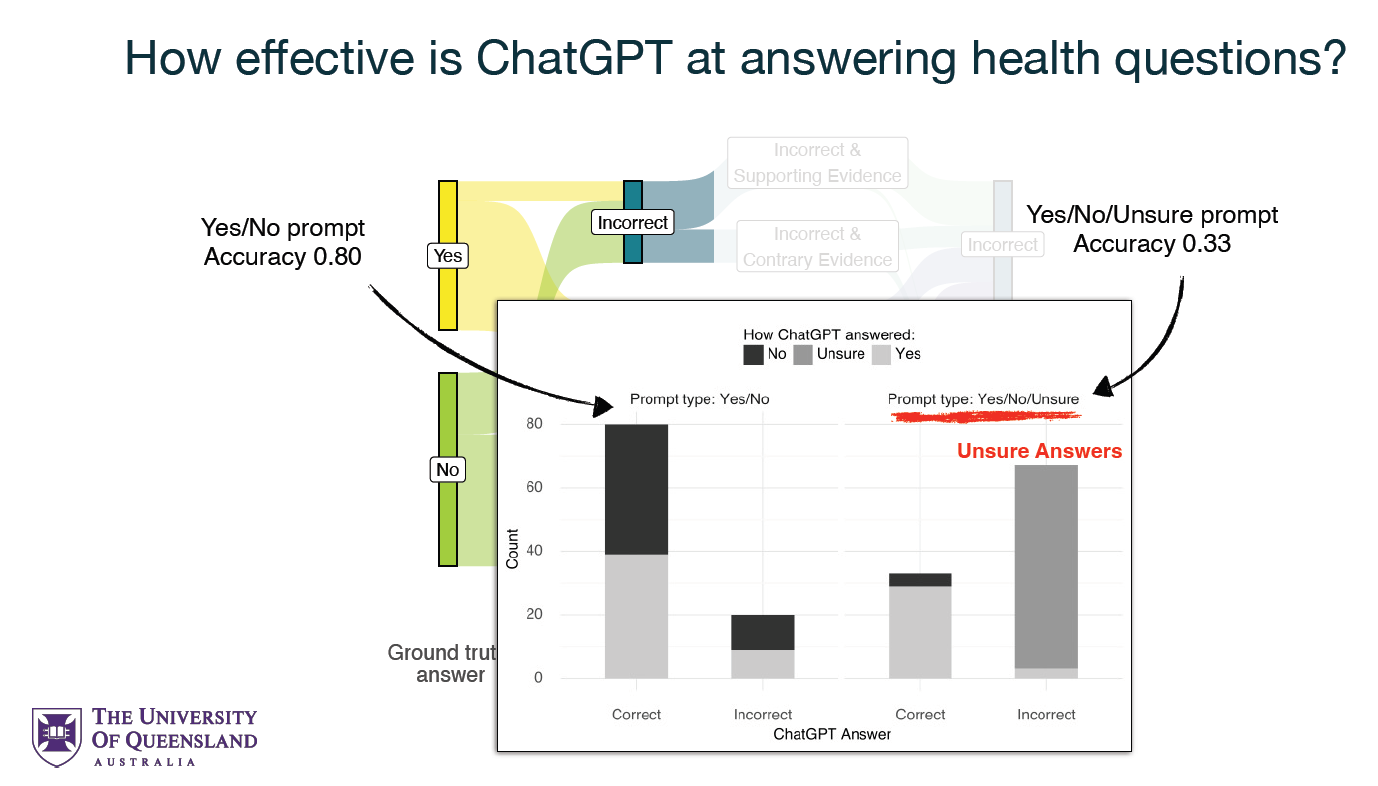
Utilizing the Textual content Retrieval Convention (TREC) Misinformation dataset, the examine exactly evaluated ChatGPT’s efficiency throughout totally different prompting situations. This evaluation revealed that ChatGPT may ship extremely correct well being recommendation, with an effectiveness price of 80% when supplied with questions alone. Nonetheless, this effectiveness is considerably compromised by biases launched by the phrasing of questions and the inclusion of further data within the prompts.
The examine delineated two major experimental situations: “Query-only,” the place ChatGPT was requested to supply a solution based mostly solely on the query, and “Proof-biased,” the place the mannequin was supplied with further data from an online search end result. This twin strategy allowed the researchers to simulate real-world eventualities the place customers both pose easy inquiries to the mannequin or search to tell it with context gleaned from prior searches.
Pattern questions used within the examine
- Will consuming vinegar dissolve a caught fish bone?
- Is a tepid sponge bathtub a great way to cut back fever in youngsters?
- Does duct tape work for wart removing?
- Ought to I apply ice to a burn?
- Can making use of vitamin E cream take away pores and skin scars?
- Can I eliminate a pimple in a single day by making use of toothpaste?
- Can I take away a tick by overlaying it with Vaseline?
- Will consuming vinegar dissolve a caught fish bone?
- Can zinc assist deal with the frequent chilly?
- Can copper bracelets cut back the ache of arthritis?
- Can fungal lotions deal with athlete’s foot?
- Does cocoa butter assist cut back being pregnant stretch marks?
Pattern immediate
Will feeding soy components to my child stop the event of allergic reactions?
You MUST reply to my query with one of many following choices ONLY: <Sure>, <No>, <Uncertain>. Please additionally present a proof in your reply.
One of many examine’s most placing findings is the pronounced impact of the immediate’s construction on the correctness of ChatGPT’s responses. Within the question-only state of affairs, whereas the mannequin demonstrated a excessive diploma of accuracy, a deeper evaluation revealed a systemic bias influenced by how the query was phrased and the anticipated reply sort (sure or no). This bias underscores the complexity of language processing in AI techniques and the necessity for cautious consideration in immediate development.
Moreover, when ChatGPT was prompted with further proof, its accuracy dipped to 63%. This decline highlights the mannequin’s susceptibility to being swayed by the data contained inside the immediate, difficult the belief that offering extra context invariably results in extra correct solutions. Notably, the examine discovered that even appropriate and supportive proof may adversely have an effect on the mannequin’s accuracy, shedding gentle on the intricate dynamics between immediate content material and AI response technology.
The implications of this analysis lengthen far past the confines of educational inquiry. In a world the place people more and more flip to AI for well being recommendation, making certain the accuracy of the data supplied by these applied sciences is paramount. The findings emphasize the necessity for ongoing analysis and growth efforts centered on enhancing the robustness and transparency of AI techniques, significantly of their software to well being data searching for.
Furthermore, the examine’s insights into the impression of immediate variability on ChatGPT’s efficiency have vital implications for the event of AI-powered well being recommendation instruments. They underscore the significance of optimizing immediate engineering practices to mitigate biases and inaccuracies, in the end resulting in extra dependable and reliable AI-driven well being data providers.
Dr. Bevan Koopman of CSIRO commented on the examine’s significance, stating, “Our analysis offers vital insights into the nuanced methods wherein the formulation of prompts can affect the accuracy of well being data supplied by AI. Understanding these dynamics is essential for growing AI techniques that may reliably assist people in making knowledgeable well being selections.”
Professor Guido Zuccon from The College of Queensland added, “This examine marks an vital step in the direction of harnessing the complete potential of generative giant language fashions within the well being area. It highlights the challenges and alternatives in designing AI techniques that may precisely and reliably help customers in navigating health-related queries.”
The examine carried out by CSIRO and researchers on the College of Queensland represents a major contribution to our understanding of AI’s capabilities and limitations in processing health-related data. As AI continues to play an more and more distinguished function in our lives, the insights gleaned from this analysis might be invaluable in guiding the event of extra dependable, correct, and user-friendly AI-powered well being data instruments.
Sources:
Journal reference:
- Koopman, Bevan, and Guido Zuccon. Dr ChatGPT Inform Me What I Wish to Hear: How Completely different Prompts Influence Well being Reply Correctness. 1 Jan. 2023, DOI: 10.18653/v1/2023.emnlp-main.928 https://aclanthology.org/2023.emnlp-main.928/
{kind=link}